Download PDF
When a distribution center begins the transition from a manual operation to an automated operation, one of the greatest challenges faced by decision makers is calculating the required throughput rates for the equipment. An automated process is not just a manual process with high-speed equipment added; automation often requires that a new approach be developed for the entire distribution operation.
Just as the automated processes are not likely to be the same as the manual processes, the factors that drive the throughput needs are not likely to be the same. Even the most thorough understanding of the requirements under the current operating conditions will not easily translate into the requirements for the new automated system.
The throughput issues that must be addressed by decision makers vary based on the challenges faced by the distribution facility as well as the unique needs of the organization contemplating the change. However, some common elements are likely to arise during any transition from a manual to an automated system:
- The effect of automated sortation on the criteria for workflow management.
- The storage and retrieval mechanisms required to support automated picking and inventory utilization strategies.
Profile of a Distribution Center
The following example, which can be considered typical of distribution center processing, will help illustrate the basic concepts required to complete an informed throughput analysis of a potential automated solution.
The distribution center receives full-carton quantities of product (pure SKU [Stock Keeping Unit] receiving cartons) and consolidates smaller quantities of multiple SKUs for customer delivery (mixed SKU shipping cartons). The distribution center does not have control over its retailers’ orders, so it cannot push residual units from open cartons to empty them. All shipped units have to be the SKUs and the quantities specified by the retailers (pull system). The operation consists of:
- 100,000 shipped units per day
- 8 operating hours per day
- 4,000 customer orders per day
- 6,000 active SKUs per day
- 40,000 active SKUs in storage
- 20 units per receiving carton (average)
Imagine that in the manual system, warehouse managers focused their concern on order profiles. Larger orders with many cartons and large quantities of units of the same SKU in each order improved the efficiency of the manual picking process by minimizing the number of rack locations that each picker needed to visit.
With the manual process, each SKU in an order represented a rack location that the picker must visit. Pickers thus would potentially need to pass every possible location to fill an order, regardless of the number of boxes comprising the order. By maintaining a high number of boxes in each order, picking could be organized such that each box was filled by passing fewer locations.
At the same time, management was under pressure from their retailers to send orders “just in time” to meet customer demand. Retailers wanted shorter lead times and wanted to place smaller, more frequent orders, replenishing sales rather than using costly floor space for a stock room or risking being out of stock on popular products. Further, retailers increasingly wanted to specify the contents of each box. These conditions reduce the ability to manage picking distances.
The Automation Answer
In the scenario described above, automating the distribution center does much more than speed the order-filling process. In an automated system, the demand to ship smaller orders no longer needs to be considered as diametrically opposed to the efficiency of the picking process.
Traditional manual systems operate under the picker-to-product principle, in which pickers with a container walk rack aisles picking the ordered units. Automated systems introduce the concept of product-to-picker processing that consists of taking the product bins to the picker’s fixed location, where the picker consolidates the shipping cartons.
Installation of an automated system, consisting of a sorter for order consolidation and an automated storage and retrieval system (AS/RS) to feed the sorter, changes the concepts used to calculate the throughput.
The Wave Concept
Sorters are particularly useful for consolidating orders that consist of many different SKUs and relatively few units per SKU. Because the sorter can consolidate many orders at the same time, all units of a given SKU that are required for numerous orders can be inducted onto the sorter at once, with only one feeding transaction from the storage location. In the manual picking operation, the picker would have visited the location for that SKU once for every order that required it.
When a sorter is used to automate the picking process, the number of orders to be consolidated concurrently becomes a much more important parameter than the number of cartons per order. Economic and operating factors are also associated with this parameter.
Furthermore, a closer examination of the storage areas may suggest that different automation requirements exist depending on the storage and transaction volume requirements of the open-case and full-case areas. Storage efficiency and throughput optimization are not mutually exclusive, but an appropriate balance of these parameters is required to maximize the return on investment of the automated facility. A segregation of the storage area based on open-case and full-case conditions is much easier to manage than the traditional fast-mover and slow-mover segregation of manual systems, and results in a more efficient system.
Proposed System Design
Consider the following system design options for our hypothetical distribution center.
If all 4,000 orders were consolidated at the same time, the facility would process one eight-hour wave (or picking cycle) per day. In order to do this, the sorter would need 4,000 drop (consolidation) points. Support systems would therefore need to feed the sorter 6,000 SKUs per day. Orders with only one SKU will complete, on average, halfway through the wave; orders with two SKUs will complete two-thirds of the way through the wave; with three SKUs, three-quarters through; and so on. Given that the orders are likely to have many SKUs, the majority of the orders would not be completed until the last part of the wave. Therefore, the facility could not begin shipping until the end of the eight-hour shift.
Another option would be to have two four-hour waves per day. In this case, 2,000 orders would be consolidated at the same time, and 2,000 sorter drop points would be required. Because the sorter would be configured with fewer drop points, a shorter overall length, and a smaller required footprint, the cost of the sorter hardware would be less than that in option #1. In addition, half the shipments could be dispatched after four hours and the other half at the end of the shift, improving the flow of work to the shipping system. However, because some of the SKUs could be requested in both waves, the number of feeding transactions increases, requiring a higher throughput rate from the system feeding the sorter and thus making that system more expensive.
In general, as the number of waves per day increases:
- The sorter required is smaller and less expensive
- Trailers can be dispatched more frequently throughout the day
- The required throughput for the feeding system increases, with a corresponding increase in cost
These three factors become the primary criteria for determining the optimum number of waves per day.
Note: The number of waves per day does not have any impact on labor requirements for the distribution center. For the purpose of this exercise, the impact of the waves per day on the distribution center operating costs is assumed to be minimal, so the waves per day were set to minimize the initial investment (waves per day = 4).
Evaluation of the Sorter Feed Operation
To this point in the evaluation, feeding transactions have been specified as SKUs going to the sorter. This concept needs to be translated into carton transactions per hour, a more standard parameter for measuring AS/RS throughput.
In a well-operated distribution center, all active SKUs will be located in storage, with no more than one residual (open) carton per SKU. Thus if 20 cartons of a particular SKU are available within the distribution center, at least 19 will be closed cases that still contain all of the units originally received. If the warehouse management software creates more than one residual carton per SKU, the storage efficiency of the warehouse decreases and the carton transactions required to feed the sorter increase.
To facilitate analysis of the feed of cartons to the sorter, the distribution center storage area will be evaluated as two distinct systems: a full-case area (only closed cases with all the original units) and a residual-case area (no more than one carton per SKU that contains fewer than the number of units originally received).
Sorter Throughput Issues
The expected required throughput—defined as cartons per wave—for feeding the sorter is a function of:
- Units per wave
- Active SKUs per wave
- Average units per receiving carton
For this hypothetical distribution center, the units per wave is calculated by dividing the units per day by the waves per day. The SKUs per wave are estimated based on the result of a shipping profile analysis. Choosing to process four waves a day yields the following values:
- 25,000 units per wave
- 2,500 active SKUs per wave
Sorter Throughput Example
Consider the following conditions. One of the active SKUs is requested by three orders in the wave, in quantities of 1 + 4 + 5, respectively, for a total of 10 units for the wave. Assume this SKU comes as 20 units to a receiving carton. There are four possible scenarios for the required carton traffic for this SKU:
The residual carton has exactly 10 units. For this condition, the carton will be sent to the sorter and nothing will return to the residual area.
The residual carton has more than 10 (and, of course, less than 20) units. For this condition, the carton will be sent to the sorter and will return to the residual area.

The residual carton has fewer than 10 units. For this condition, the carton will be sent to
the sorter and will not return to the residual area; however, a full-case carton must be sent to the sorter, partially emptied, and returned to the residual area.
No residual carton is available for that SKU. For this condition, no carton will come to the sorter from the residual area, a full-case carton will be sent to the sorter to be partially emptied, and that carton will return to the residual area.
For each condition with the exception of #4, a carton needs to come from the residual area to the sorter. The probability of #4 occurring is:
1 / (units per receiving carton) = 1 / 20
The probability of #4 not occurring is then 19 / 20. This is also the probability of one carton being sent from the residual-case area to the sorter per active SKU in the wave.
For each condition with the exception of #1, a carton must return to the residual area from the sorter. The probability of #1 occurring is 1 / 20. The probability of #1 not occurring is 19 / 20, which is also the probability of one carton returning to the residual area from the sorter per active SKU in the wave.
If a dual transaction is defined as one carton going from the residual area to the sorter and one carton going from the sorter to the residual area, the total number of dual carton transactions per wave can be calculated as follows:
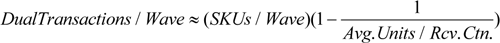
In this example, the expected number of dual transactions per wave between the residual area and the sorter would be:
DualTransactions / Wave = (2,500)(1-(1/20))=2,375
Once the expected transactions between the residual area and the sorter have been determined, the expected transactions from the full-case area to the sorter must be calculated. To accomplish this, the flow into and out of the residual area must first be examined.
During normal operation, units are sent from the residual area to the sorter to complete orders (scenarios #1, #2, and #3), and other units, originally in full-case cartons, are sent to the residual area (scenarios #3 and #4). The net flow of units into and out of the residual area must be zero; otherwise, the residual area would be flooded or empty after some period of operation. If the net flow of units into and out of the residual area during a wave is zero, the total number of units sent to the sorter to complete orders has to come from the full-case area—not as the same SKU mix, but as the same total number of units. Therefore, the expected transactions between the full-case area and the sorter per wave are:
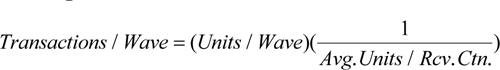
Given that the cartons sent from the full-case area to the sorter need to be replaced with new cartons sent from receiving to the full-case area, these transactions would also be dual transactions.
In this example, the expected dual transactions for the full-case area would be:
DualTransactions / Wave = (25,000)(1/20)=1,250
The total number of dual transactions per wave is the number of dual transactions for the residual area and dual transactions for the full-case area combined, or:
TotalDualTransactions / Wave = 2,375 + 1,250 = 3,625
For a series of four two-hour waves (eight hours per day divided by four waves per day), the required number of dual transactions per hour for the AS/RS is:
TotalDualTransactions / Hour = 3,625 / 2 = 1,813
Throughput Solutions
For an automated warehouse system consisting of a sorter and an AS/RS to feed the sorter, the required sorter drop points are:
Orders/Day
Waves/Day
and the AS/RS required dual transactions per hour are:
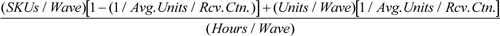
The distinction this example makes between full-case and residual storage areas illustrates their differences. The full-case area contains most of the distribution center’s inventory, but requires fewer transactions. The residual area, by comparison, has small storage requirements, but must facilitate a greater number of transactions. In other words, the full-case area has high storage requirements and low throughput requirements, while the residual-case area has high throughput requirements and low storage requirements.
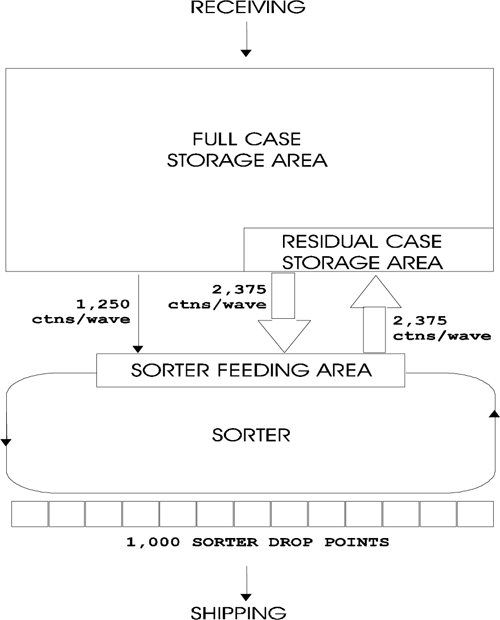
Based on the preceding analysis, the full-case and residual storage areas clearly have different requirements that justify different recommended solutions. The money spent in the full-case area should focus more on efficient storage capacity and less on efficient/fancy throughput capabilities (i.e., conventional rack with manned vehicles). On the other hand, investment in the residual area should be directed at high and efficient throughput capabilities with less emphasis on storage efficiency (i.e., AS/RS, stackers, carrousels). The segregation of the storage area into residual and full-case areas does not present the problems that the segregation of fast and slow movers does. There is no need to define which SKUs are fast movers and which are slow movers, to re-evaluate categories periodically, or to move SKUs from one area to another as their status changes.
The change from a manual operation to an automated system forces decision makers to develop a new view of the warehouse and the factors driving it. Distribution center managers will achieve better results if the requirements for the entire operation are considered as a whole, rather than attempting to automate individual parts of a manual system.
